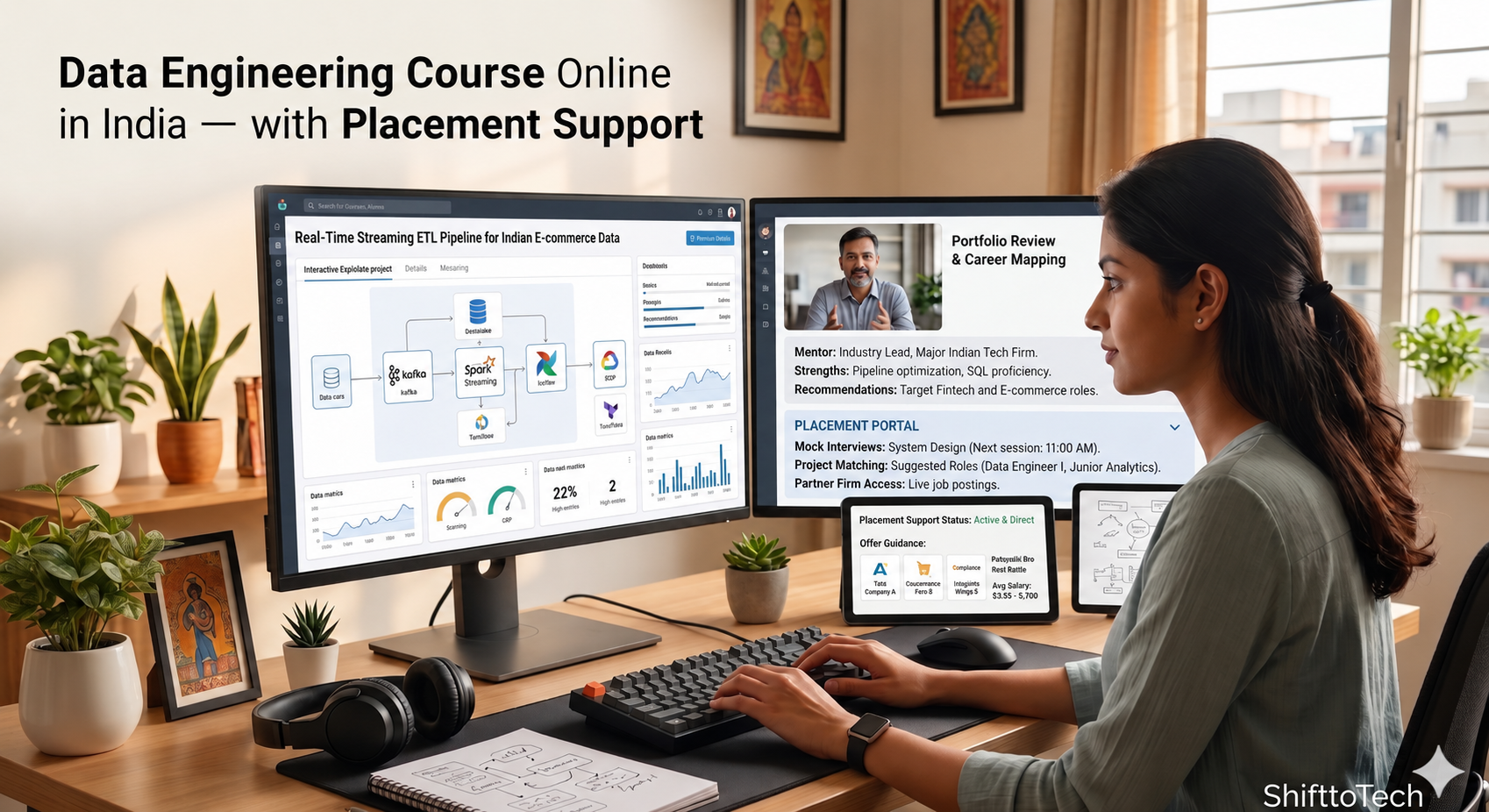
20,000+ data engineering jobs open across India — and most candidates fail the first round because they can't explain how a real pipeline runs in production. You'll build SQL, Python, Spark, Kafka, Databricks, Snowflake, dbt & AWS pipelines live, deploy them on cloud, and defend your choices in mock interviews. Exactly like you will in a real one.
This isn't hype. Every company that runs on data (which is every company now) needs someone to build and maintain the pipelines that move it. Here's what the numbers actually say.
That's one city. Add Hyderabad (5,679), Delhi NCR (2,650), Pune, Mumbai — you're looking at 20,000+ openings across India. BFSI accounts for 57% of this demand.
The full range is ₹6–32 LPA. But Databricks and Snowflake specialists command 20–40% more than generalists at the same experience level. Tool choice matters more than years of experience.
Barclays, JPMorgan, Goldman Sachs, HSBC — their India GCCs aren't back offices anymore. They build core data infrastructure. And they pay accordingly because they need people who understand compliance.
NASSCOM's numbers. And every AI system needs a data pipeline feeding it. Engineers who build AI-ready infrastructure — vector stores, feature pipelines, embeddings — earn ₹30–45 LPA at product companies. That's Level 2 territory.
We didn't pick these tools because they look good on a syllabus. We pulled 29,000+ job descriptions from Naukri, LinkedIn, and Glassdoor and taught the tools that appeared most often. If recruiters don't filter for it, we don't waste your time on it.
 PostgreSQL
PostgreSQL Python
Python Pandas
Pandas Apache Spark
Apache Spark Apache Kafka
Apache Kafka Apache Airflow
Apache Airflow Databricks
Databricks Snowflake
Snowflake dbt
dbt AWS
AWS Docker
Docker Terraform
Terraform Power BI
Power BI Git/GitHub
Git/GitHub Linux
Linux Gen AI / RAG
Gen AI / RAGWe scanned 29,000+ live data engineer job postings to build this. Every topic maps to something a recruiter tests for. Two levels — take one or both. Each one stands alone.
We pulled these from Glassdoor (19,897 salary submissions) and PayScale — June 2026. Not projections. What people with these skills are actually getting paid right now, broken down by company type.
Scaler runs 200+. UpGrad runs 50+. Almabetter similar. We cap at 10. If you're confused about why your Spark job failed, you get to ask — not wait three days for a "mentor" to respond on a forum.
Not someone who "worked in data for 10 years" and now trains full-time. A working DevOps + Data engineer who deployed a Terraform module last week and can tell you exactly what went wrong and why.
No 45-minute slides followed by 15 minutes of "practice." You open your laptop, connect to a real database, write queries against real data, deploy to real AWS. Every class. From Day 1.
Terraform, Docker, CI/CD for data pipelines, DPDP Act compliance, data contracts. Ask any GCC recruiter — these are the skills that get resumes past the filter. Every other institute stops at Spark and calls it advanced.
Live online. If you miss a session, the recording is shared within hours. No penalty, no "you missed it, too bad." Life happens. We plan for it.
ATS-optimized resume. LinkedIn overhaul. Mock interviews modeled on what Barclays, Flipkart, and Amazon actually ask. Salary negotiation — because the difference between accepting the first offer and negotiating is often ₹3–5 LPA.
No hidden charges. No "contact us for pricing." Here's every number upfront. EMI available if you need to split payments.
If you're thinking about enrolling, chances are your question is already answered here.